| Attachment | Size |
|---|---|
| 5.68 KB | |
| 6 KB |
Document Length and Relevance Ranking
In Part 1, we made the argument that the one to two orders of magnitude of difference in document length between HathiTrust books and the documents used in standard test collections affects all aspects of relevance ranking.
Most relevance ranking algorithms used for ranking text documents are based on three basic features[i]:
- Document Frequency: the number of documents containing a query term.[ii]
- Term Frequency: the number of times a query term occurs in the document.
- Document Length: the number of words in the document.
Both document frequency and term frequency are affected by document length.
Inverse Document Frequency (idf)
When a query contains several words, all of the words may not be equally important or equally useful in finding relevant documents. The fewer documents that contain a term, the more useful that term is in discriminating between relevant and irrelevant documents. For example, in the HathiTrust collection, for the query [the green aardvark] - the word “the” occurs in most documents (about 75%), the word “green” occurs in a medium number of documents (about 41%), and the word “aardvark” occurs in very few documents (about 0.16%).[iii] Therefore, for the HathiTrust collection, the word “aardvark” is a better discriminator between relevant and irrelevant documents than either “green” or “the”. If we had three documents each containing only two of the three query terms, a document containing only the two query terms “green” and “aardvark” would rank highest because these terms occur in the fewest documents. A document containing only the two query terms “the” and “green” would rank lowest because the words “the” and “green” occur in the most documents.[iv]
In ranking, we want to give higher scores to words that will be more useful in identifying relevant documents, so words occurring in fewer documents should get higher scores. To accomplish this, a mathematical function is used that gives higher scores to words occurring in fewer documents. This function is called inverse document frequency or idf.
To understand the effects of document length on inverse document frequency, it will be helpful to look at how document length affects the number of unique terms in a document. As document size increases, the number of unique terms in a document increases.[v]
In the chart below, the average number of unique terms per document for two Text REtrieval Conference (TREC) test collections is compared with the average number of unique terms in HathiTrust documents.[vi]
Table 1: Unique terms
|
TREC AP |
TREC FR |
HathiTrust (estimated) |
|
|
Avg Unique Terms |
144 |
188 |
20,000 |
|
Max Unique Terms |
690 |
7,947 |
386,366 |
|
Avg Doc Length |
375 |
1,050 |
100,000 |
As the total number of unique words in a document increases, the probability that any particular word occurs in a document increases, and the percent of documents containing a particular term increases. This has two implications for relevance ranking algorithms:
- Long documents are more likely to be retrieved than short documents, because they have a larger number of unique words.
- As document length increases, the number of documents containing a particular word will increase, since there are more unique words in longer documents. This means that searches in collections of very long documents will tend to retrieve a very large number of documents. This has implications for assessing recall/precision trade-offs.
The chart below shows the relative document frequency for terms from a TREC query [tropical storms] and a query from the HathiTrust query logs [mother earth]. For HathiTrust, the chart shows the document frequency for both a page level index (each page of a book is a Solr document) and our regular book level index.[vii]
Table 2: Percentage of total documents containing term
|
Term |
TREC 45-CR |
HT Page lvl |
HT Book lvl |
|
Tropical |
0.24% |
0.27% |
14.91% |
|
Storms |
0.20% |
0.38% |
13.59% |
|
Mother |
1.76% |
1.38% |
32.38% |
|
Earth |
1.23% |
1.37% |
35.13% |
|
Average Doc Size |
500 |
350 |
100,000 |
Terms that would be good discriminators in the TREC collection or the HT page level index, because they are relatively rare (they occur in fewer than 2% of all documents), are not very good discriminators in the HathiTrust Book collection index. “Mother” and “earth” occur in nearly one third of all documents in HathiTrust.[viii] Algorithms that use idf (such as the vector-space model , Lucene’s default algorithm, and BM25), seem unlikely to work well with the book-length documents in the HathiTrust collection. [ix]
Since many terms occur in a relatively large proportion of the long documents in the HathiTrust collection, querying this collection will tend to produce a very large number of results. Because it is so easy to get very large result sets, much attention has to be paid in configuring the search engine to favor precision over recall.[x]
Term Frequency (tf)
The more times a term is used in a document, the more likely it is that the document is about the concept expressed by that term. Most relevance ranking algorithms use a function based on the number of times a term occurs in a document, i.e. term frequency or tf.[xi]
As document size increases, the range of tf values increases.[xii] In the table below, the maximum term frequencies for two terms from a user query, [mother earth] and a TREC query ,[tropical storms] are listed for various document sizes. Additionally, the statistics are also shown for the word “he”, which is a very frequent word ( usually considered a stop word) in the newswire-based TREC collections. As can be seen, the possible range of term frequencies is about two orders of magnitude greater for book length documents than for smaller documents such as the newswire articles used in the TREC ad hoc collections or the HathiTrust documents indexed on the page level. We believe that it is unlikely that algorithms that have been tested and tuned on smaller documents will work well with large documents. [xiii]
Table 3: Maximum Term Frequency
|
|
TREC 45-CR |
HT Page level index |
HT Book level index |
|
Tropical |
17 |
76 |
2,451 |
|
Storms |
10 |
47 |
1,104 |
|
Mother |
50 |
191 |
4,247 |
|
Earth |
57 |
314 |
2,506 |
|
He |
172 |
403 |
45,689 |
|
Average Doc Size |
500 |
350 |
100,000 |
Tuning algorithms
The default settings for parameters that are incorporated into most implementations of the newer algorithms are based on settings that have been shown to work well on the TREC collections of relatively small documents. These settings are unlikely to work well with documents that are one to two orders of magnitude larger than the documents used to determine the default settings. When there is no training data available to tune parameters, researchers often use the defaults. However, with long documents the defaults are unlikely to be appropriate. As one example, in some of theINEX Book Track runs, the BM25 algorithm was used with its default settings for relevance ranking whole books.
The BM25 algorithm has a tuning parameter, k1, which has a default value of 1.2. The recommended range for tuning k1 is between 1.2 and 2.[xiv] The equation below shows the part of the BM25 algorithm that creates a relevance weight (part of the total relevance score) based on the term frequency (tf) and the tuning parameter k1. The chart below shows the impact of setting BM25’s k1 parameter to 1, 2, and 3 as tf increases from 1 to 100 . [xv]
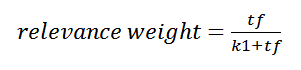
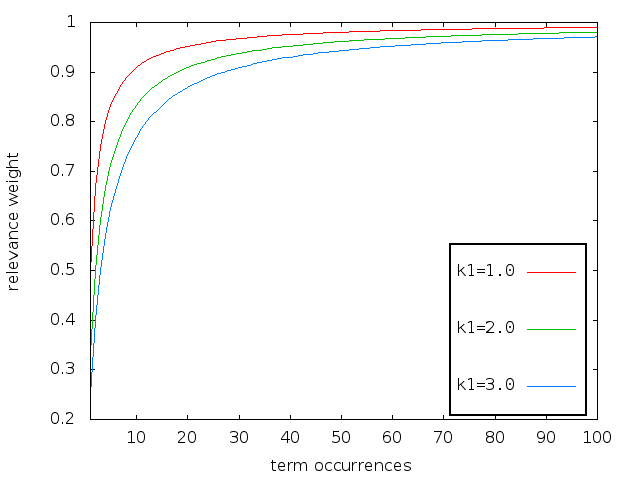
As you can see, the function is very sensitive to the number of term occurrences between 1 and 10 occurrences, but gets much less sensitive as the number of occurrences goes up. The curves tend to level out somewhere between 40 and 60. That is, after somewhere around 50 occurrences of a term, additional occurrences of the term make very little difference to the relevance weight. This is fine for TREC ad hoc collections where the maximum term frequencies (excluding stop words) are in the range of 1-60.[xvi] For book-length documents, using these values would mean that the ranking formula would not be able to meaningfully distinguish between a document where a term occurred 100 times and a document where it occurred 1,000 times. As table 3 shows, query term frequencies in the HathiTrust book collection can easily exceed 1,000 occurrences.
The figure below, shows tf increasing from 1 to 1,000 (a more realistic range for the HathiTrust book collection). In this figure BM25’s k1 parameter was set about ten times the defaults, i.e. 10, 20, and 30.
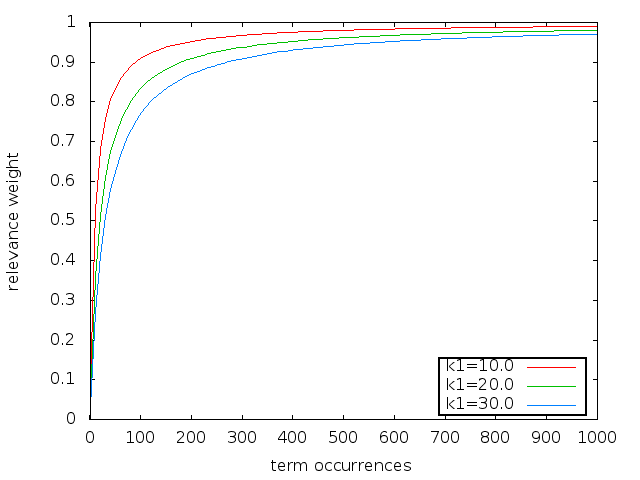
Clearly, the k1 parameter should be set significantly higher than the default for ranking book length documents
While it seems clear that the parameters for BM25 need to be tuned to accommodate long documents, it is an open question whether, even with tuning, BM25 would work with book length documents. BM25 uses idf weighting to help discriminate between relevant and irrelevant documents. We saw earlier that idf weighting is unlikely to be effective with long-documents. We also suspect that the relationship between term frequency and relevance is fundamentally different for short documents, such as the newswire articles and truncated web pages used in research test collections, than for long documents like books. The relationship between term frequency and relevance will be discussed further in future blog posts.
Notes:
[i] See Fang et al. (2011) for a detailed discussion of these three features and how they are operationalized in several current retrieval algorithms. Raw term frequencies or document frequencies are not often used. Term frequencies tend to follow a zipf-like distribution so sub-linear functions of term frequency are often used. Tf and idf functions that are applied to raw term frequencies or document frequencies are called term weighting. See Salton and Buckely (1988) for an early exploration of term weighting approaches and Zobel and Moffat (1998) Cummins (2006) and Goswami (2014) more recent explorations of possible ways to implement tf, idf, and length normalization.
[ii] Some algorithms use the total number of occurrences of a query term in the collection rather than the number of documents in the collection containing the term. Lucene, BM25, and the vector space model use inverse document frequency. The DFR and Information-Based models have options to use either document frequency or total term frequency (number of occurrences in the collection.)
[iii] The actual counts as of March 31, 2014 are:” the”: 8.3 million, “green”: 4.6 million, and “aardvark”:17,6 thousand. Total documents: 11.1 million.
[iv] See “the idf page” http://www.soi.city.ac.uk/~ser/idf.html for more background on idf.
[v] See Heaps law: http://en.wikipedia.org/wiki/Heaps%27_law
[vi] TREC data comes from Singhal (1997). The counts for HathiTrust were estimated based on a random sample of 1,000 English language documents and a large dictionary chosen on the basis of its size (for max unique terms). In a corpus of 10 million books, this is obviously too small a sample to be accurate, but we believe this shows the order of magnitude of the differences.
[vii] See http://www.hathitrust.org/blogs/large-scale-search/tale-two-solrs-0 for a discussion of indexing at the whole book versus the page level.
[viii] Lupu and Hanbury (2013: p 31-32) point out that the relatively long documents in patent literature collections have a similar issue in that many terms occur in 25% or more of the collection.
[ix] Lucene commiter Robert Muir, suggested that algorithms that use total term frequency (also called collection frequency) such as DFR and the Information-Based models, might work better with our long documents due to this issue with idf. (email to Tom Burton-West Aug 24, 2011.)
[x] Because very large numbers of documents are likely to be returned, we currently take several measures to favor precision over recall in configuring HathiTrust full-text search. We set the default operator to a Boolean “AND” and we generally avoid stemming and the use of synonyms (which increase recall). We also decided not to use a mix of unigrams and bigrams for CJK retrieval and only use bigrams to favor precision over recall.
[xi] Raw term frequency is rarely used in tf*idf relevance ranking. Generally some kind of sub-linear function is used. Lucene uses the square root of the term frequency, many other algorithms use a log function. See references in note i for further discussion.
[xii] Term frequencies are generally distributed according to Zipf’s law (Baroni 2009)
[xiii] As noted by Fang et.al. (2004)”…Despite this progress in the development of formal retrieval models, good empirical performance rarely comes directly from a theoretically well-motivated model; rather, heuristic modification of a model is often necessary to achieve optimal retrieval performance..” In practice implementations of formal models are tested against some set of collections and modified to optimize performance. For example BM25 while inspired by a formal model, was developed empirically by testing over 25 different variations of the algorithm on a number of different TREC collections. Since none of the models has been systematically tested on long documents such as books, it is not known whether or not they would need some additional modification.
[xiv] See Roberson and Zaragoza (2009:p360.)
[xv] In BM25 the amount of increased score for an increase in tf falls off as tf gets higher. The k1 parameter controls the rate at which this falls off and eventually approaches a straight line (i.e. after tf gets above some level, an increase in tf results in a very small increase in score.) This is called the BM25 term saturation function.
[xvi] “he” with a max tf of 172 is considered a stop word.
References
M. Baroni. 2009. Distributions in text. In Anke Ludeling and Merja Kyto (eds.), Corpus linguistics: An international handbook, Volume 2, Berlin: Mouton de Gruyter: 803-821. http://sslmit.unibo.it/~baroni/publications/hsk_39_dist_rev2.pdf
Ronan Cummins and Colm O'Riordan. 2006. Evolving local and global weighting schemes in information retrieval. Inf. Retr. 9, 3 (June 2006), 311-330. DOI=10.1007/s10791-006-1682-6 http://dx.doi.org/10.1007/s10791-006-1682-6
Goswami, P., Moura, S., Gaussier, E., Amini, M., & Maes, F. (2014). Exploring the space of IR functions. In M. Rijke, et al. (Eds.), (pp. 372-384) Springer International Publishing. http://dx.doi.org/10.1007/978-3-319-06028-6_31
Hui Fang, Tao Tao, and ChengXiang Zhai. 2004. A formal study of information retrieval heuristics. In Proceedings of the 27th annual international ACM SIGIR conference on Research and development in information retrieval (SIGIR '04). ACM, New York, NY, USA, 49-56. DOI=10.1145/1008992.1009004 http://doi.acm.org/10.1145/1008992.1009004. copy on author's web site
Hui Fang, Tao Tao, and Chengxiang Zhai. 2011. Diagnostic Evaluation of Information Retrieval Models. ACM Trans. Inf. Syst. 29, 2, Article 7 (April 2011), 42 pages. DOI=10.1145/1961209.1961210 http://doi.acm.org/10.1145/1961209.1961210 copy on author's web site
Lupu, M. and Hanbury, A. 2013. Patent Retrieval. Foundations and Trends in Information Retrieval 7, 1 (Feb. 2013), 1‐97. DOI: http://dx.doi.org/10.1561/1500000027. copy on author's web site
Stephen Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework. Now Publishers Inc., Hanover, MA, USA. copy on author's web site
Gerard Salton and Christopher Buckley. 1988. Term-weighting approaches in automatic text retrieval. Inf. Process. Manage. 24, 5 (August 1988), 513-523. DOI=10.1016/0306-4573(88)90021-0 http://dx.doi.org/10.1016/0306-4573(88)90021-0
Amitabh Kumar Singhal. 1997. Term Weighting Revisited. Ph.D. Dissertation. Cornell University, Ithaca, NY, USA. UMI Order No. GAX97-14899. http://ecommons.cornell.edu/bitstream/1813/7281/1/97-1626.pdf
Justin Zobel and Alistair Moffat. 1998. Exploring the similarity space. SIGIR Forum 32, 1 (April 1998), 18-34. DOI=10.1145/281250.281256 http://doi.acm.org/10.1145/281250.281256