Forty days forty nights: Re-indexing 7+ million books (part 1)
Forty days and forty nights; That’s how long we estimated it would take to re-index all 7+ million volumes in HathiTrust. Because of this forty day turnaround time, when we found a problem with our current indexing, we were reluctant to do a complete re-index. Whenever feasible we would just re-index the affected materials.
Over the last year we have been receiving materials from a large number of HathiTrust members. Despite various quality control and validity checking measures, we occasionally do not detect a problem until several hundred thousand records have been indexed incorrectly. As a result, we realized that we need to be able to rapidly re-index the entire repository whenever a problem is found with the indexing process.
We also want to be able to take advantage of improvements to Solr and Lucene and make other changes which might require re-indexing.
Among those changes are:
- Adding bibliographic metadata so that we can provide faceted searching and improved relevance ranking
- Improve searching for non-Latin scripts such as CJK and Hindi
- Improve tokenizing to reduce the large number of terms caused by the interaction of dirty OCR and our Solr analysis chain.
Speeding up indexing
The HathiTrust indexing system
Our indexing set-up involves a configurable number of document producers that take a group of document ids from a shared indexing queue and then create Solr documents from the repository and send the documents to one of twelve shards. In order to distribute documents evenly (to partially ameliorate Solr’s lack of global idf,) each producer sends documents to shards on a round-robin basis. When a producer sends a document to a shard for indexing, it waits until it gets a response back from Solr before moving on to send the next document. If the response from Solr indicates some kind of error or if there is an error in the document creation process, an entry is made in an error table in the database. This allows us both to troubleshoot errors and to re-queue the documents for indexing once the errors are fixed. Because we don’t want two copies of a document in the index to be created when a document gets re-indexed, the producers consult a database which keeps track of which documents are indexed in which shard.
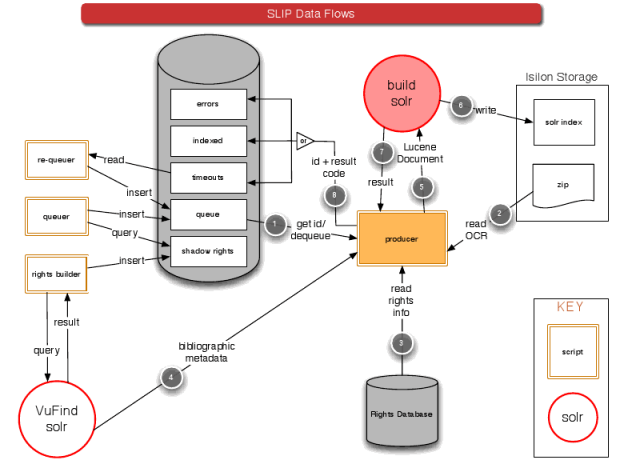
Large Scale Search Indexing Architecture (1)
We generally run around 4-8 producers on each of 5 machines. (Note: the diagram below was created when we were running 10 shards, we now run 12)
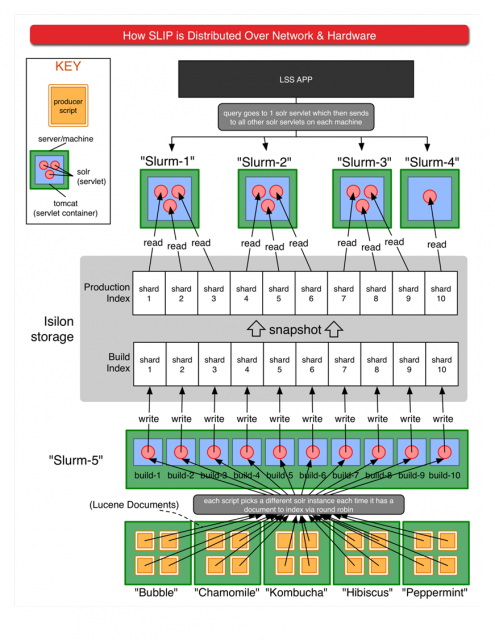 Large Scale Search Indexing Architecture (2)
Large Scale Search Indexing Architecture (2)
We have observed that the producers can produce and send Solr documents faster than Solr can index them. When we first start indexing, the indexing rate is relatively fast but as the size of the index increases the indexing rate decreases. Once the index size for each shard got over about 50 GB, the indexing rate decreased significantly and the overall average rate for the run was about 600 documents per hour per shard. At the end of the run when all 7+ million documents are indexed and we optimize each index, each of our indexes is between 400-500GB. We suspected that the decrease in speed is due to the disk I/O required for large merges. In order to understand the impact of merges on indexing speed and how this might be tuned we need to discuss Lucene’s index merging process.
Lucene’s index merging process
Lucene’s index merging algorithm is an elegant solution to the “inverted index dynamic update problem.” Early search engines were not able to incrementally update an index. What they did was rebuild the entire index and then swap the new index with the old index. The problem lies in the nature of inverted indexes. For several reasons, including efficient compression and decompression of postings, the inverted index stores postings for each term in term order and then in document order.
As an example suppose we have written an index for 8 documents to disk and it contains the following fragment of a postings list where we have indexed 8 documents and the numbers are the document id numbers of documents containing the words listed.
aardvark:2|....|cat:1,3,4,7|dog:2,4,7,8|...|zebra:2,7
If we add document number 9 and it contains the word cat, the document number has to be inserted in the file at the end of the cat postings and before the dog postings.
aardvark:2|....|cat:1,3,4,7,9 |dog:2,4,7,8|...|zebra:2,7
This requires reading the whole index into memory (possibly a little at a time), inserting the new postings in the proper places, and writing them back out to disk. Since the on-disk index is usually compressed in order to reduce disk I/O, the additional steps of uncompressing the index upon reading and compressing the index upon writing need to be added. In Lucene, these steps require significant processing resources.
As the index gets larger, rewriting the whole index becomes increasingly expensive. Alternatives to rewriting the whole index include leaving empty space at the end of the postings for each word and other methods of shuffling bits around. ( See Buttcher & Clarke and or http://nlp.stanford.edu/IR-book/html/htmledition/dynamic-indexing-1.html for details) Lucene deals with this problem by what is called logarithmic or geometric merging (Lester, N., Moffat, A., & Zobel, J. (2005), Büttcher, S., & Clarke, C. L. A. (2005)).
Lucene creates a series of self-contained indexes (called segments) and at search time searches each of the indexes and combines the results. The indexing process starts by the creation of an in-memory index in a RAM buffer. When the buffer is full it writes the index as a new segment on disk. The defuault size of the RAM buffer is set in the solrconfig.xml file. Here are the default settings from the Solr example solrconfig.xml:
<ramBufferSizeMB>32</ramBufferSizeMB>
If there are too many segments, searching performance will slow down, so Lucene uses a merging strategy to merge some number of segments into a larger segment.The number of segments is set in solrconfig.xml as the mergeFactor. Here are the default settings from the Solr examle solrconfix.xml
<mergeFactor>10</mergeFactor>
As indexing continues, when the number of segments written to disk reaches a number specified by the “mergeFactor” those segments are merged into a larger segment. For example with the default Solr settings for the RAM buffer of 32MB and mergeFactor of 10, when the tenth 32MB segment is about to be written to disk, Lucene merges all the segments into a 320MB file. When there are ten 320MB files they are merged into a 3,200MB file etc. (see the diagram and algorithm discussion in Doug Cutting's pisa lecture: http://lucene.sourceforge.net/talks/pisa/ )
Here is a chart showing segments 32MB, 320MB etc, on a log scale:
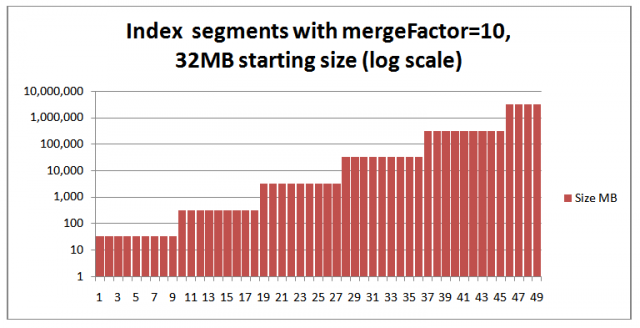
Index segments wi 32MB starting size and mergeFactor=10
The chart above assumes that segment sizes are exact multiples of the ramBufferSizeMB of 32MB. In practice segment sizes are only approximately the same size. The chart below shows actual segment sizes in bytes from one of our 700,000 document indexes. The smallest segment is about 3KB, the largest segment is 130 GB and the total size is around 415 GB.
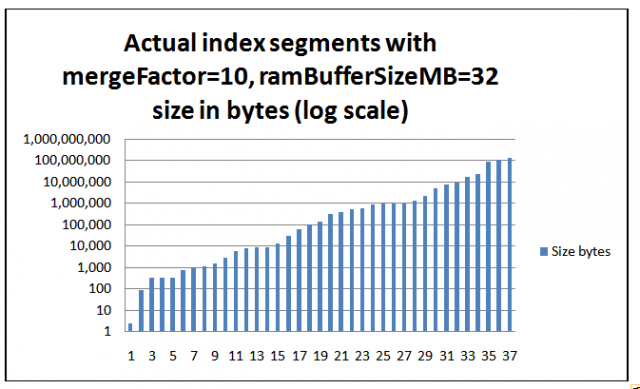
Actual index segments: mergerFactor=10, ramBufferSizeMB=32, size in bytes (log scale)
We need the fastest search performance we can get so we optimize our indexes on a nightly basis on a separate Solr instance and then mount the optimized index the next day for searching on our Solr search servers. Optimizing the index merges all the segments into one large segment
Tuning Solr’s indexing settings
Changing the ramBufferSizeMB
We started with the default Solr configuration of 32MB for ramBufferSizeMB and the default mergeFactor of 10. Our first thought was that if we could increase this to 320MB, we could do a lot more work before writing to disk and save a huge number of intermediate merges. Our reasoning was that with the default settings after nine 32MB segments are written to disk, when the 10th one is about to be written to disk a merge would get triggered and the 9 32MB segments would have to be read from disk, merged with the in-memory 32MB segment and then written out to a 320MB segment. This reading of 288MB of data from disk (9*32MB) and writing of the 320MB would happen about 1000 times for our 320GB index. By changing the ramBufferSizeMB to 320MB all this merging would take place in memory and there would just be a write to disk, avoiding the overhead of reading the 9 32MB segments 1,000 times thus saving about 288GB of disk reads.
Extending this reasoning, it would seem that we would want to set the ramBufferSizeMB to as large a value as possible. A query to the list suggested that a 2048MB limit was written into the code, but that several Solr users had experienced poor performance due to Java garbage collection issues . (http://lucene.472066.n3.nabble.com/What-is-largest-reasonable-setting-for-ramBufferSizeMB-tc505964.html )
Changing the mergeFactor
Since we eventually optimize the index into one large segment, our second idea was to eliminate lots of intermediate merging by using the Lucene “noOp” merge policy and just run an optimize after all indexing is complete.(https://issues.apache.org/jira/browse/LUCENE-2331 http://lucene.472066.n3.nabble.com/Using-NoOpMergePolicy-Lucene-2331-from-Solr-tc760600.html) If we put the ramBufferSizeMB to around 2 GB, we would have between 150 and 200 segments to merge. We planned to increase the maximum number of open filehandles to accomodate this, but we also had a few concerns about memory.
We posted some questions about this to the list. Michael McCandless pointed out that in addition to being I/O intensive, merging also involves high CPU and memory use because the on-disk files have to be read into memory and uncompressed, then merged, and then the resultant merged file has to be compressed. He suggested that having some intermediate merging prior to optimization would allow us to take advantage of parallelization, (http://lucene.472066.n3.nabble.com/Experience-with-large-merge-factors-tc1637832.html)
Benchmarking
We decided that what we wanted to do is experiment with different ram buffer sizes and merge factors. We initially thought we would be able to use the Lucene benchmarking framework in contrib. There is an example in the Lucene in Action book of running a benchmark with different ram buffer sizes (Appendix C.2 p 447). We looked into this a bit more and realized that we would need to either write Lucene code to duplicate the various filter chains in our Solr schema or write code to enable the Lucene Benchmark to read Solr configuration information. (
http://lucene.472066.n3.nabble.com/Using-contrib-Lucene-Benchmark-with-Solr-tc2755591.html and
https://issues.apache.org/jira/browse/LUCENE-3010)
Comparing Apples and Oranges *
There is a general problem with benchmarking indexing when changing any parameters that might change the number of merges (See Lucene in Action section 11.1.2). Suppose for example you have a mergeFactor of 10 and are experimenting with different ramBuffer sizes. If run A finishes with 9 medium size segments but run B creates slightly smaller segments which results in 10 medium segments triggering a large merge, run B ends up doing significantly more work. So run B might take significantly longer. However, if the tests were repeated with enough more documents to trigger the merge for run A as well, the work and the times would likely be more comparable. The big question is how to compare runs which result in a different end state in terms of segments and segment sizes in a meaningful way.
The indexwriter log
As a baseline we ran a test with our current configuration (which uses the Solr defaults of ramBufferSizeMB=32 and mergeFactor= 10 ) and turned on index logging in solrconfig.xml:
<infoStream file="${solr.indexwriter.log.dir}">true</infoStream>Our average document size is about 800K or about 0.8 MB, so we assumed that with a ramBufferSizeMB of 32 MB, we would get somewhere between 30 and 40 documents indexed before the ramBuffer writes to disk. We checked this by analyzing one of the statistics that the indexwriter log prints out: “numDocs” which is the number of documents in the index segment that is written when the ramBuffer is flushed to disk.
DW: flush postings as segment _13 numDocs=10
What we discovered was that about 70% of the flushes were for only 1 document and 90% were for 5 or fewer documents. It turns out that the in-memory data structures used for indexing trade memory use for speed of indexing operations and index segments with a large number of unique terms take up a large amount of memory.* Because we have documents in over 400 languages and lots of dirty OCR, we end up with large numbers of terms. Obviously flushing to disk after every document rather than buffering 30-40 documents is a performance hit. So the default Solr ramBufferMB size of 32MB is way too low for efficient indexing of our documents.
The indexwriter log provides some other statistics which pretty much echo the fact that the large number of unique terms in our corpus cause the in-memory index structure to consume a lot of memory.
http://www.lucidimagination.com/search/document/d76c7a9f777f02b6/understanding_the_indexwriter_infostream_log#ed9e99c0019adc4b
Mike McCandless has added some code on trunk that allows the measurement of the “write amplification” or the ratio of the amount of data read and written to disk to the size of the final index. He also has some nice visualizations. We hope to use this code, but will have to tweak the time compression since even an indexing geek will not want to watch a 10 hour video of our index. http://blog.mikemccandless.com/2011/02/visualizing-lucenes-segment-merges.html.
Tweaking the Merge parameters
For our test we made the following changes:
- Changed the merge scheduler from serialMergeScheduler to concurrentMergeScheduler
- Increased ramBufferSizeMB from 32MB to 960MB
- Increased mergeFactor from 10 to 40.
1 Changed serialMergeScheduler to concurrentMergeScheduler
Our production configuration had its origins in an older version of Solr before the concurrentMergeScheduler was available. With the serialMergeScheduler indexing is halted during a merge. With our default settings and an average of 1 documents being written to disk when the ramBuffer was full, this means a merge was triggered after every appoximately 10 documents. Even if merging is fast, halting indexing with every 10 documents is a huge slowdown when you have millions to index. With the concurrentMergeScheduler indexing continues in a separate thread.
2 Increased ramBufferSizeMB from 32MB to 960MB
This does more work in RAM before writing to disk and eliminates lots of very small reads and writes.
3 Increased mergeFactor from 10 to 40.
This increases the amount of time between merges and the size of the merges when merges do occur. The net result is fewer intermediate merges.
On our test server we used this setup to index one shard’s worth of documents which is about 700,000 documents. When we got around 680,000 documents indexed we hit java Out of Memory errors (OOM’s) and had to stop the indexing.
Too Many Words Yet Again!
We wrote to the list to try to determine whether the larger ramBuffer size and/or the larger number of segments merging were what caused the OOM’s. (http://lucene.472066.n3.nabble.com/Memory-use-during-merges-OOM-tc2095600.html) After some back and forth on the list and running jmap to peek at what was taking up memory we discovered that even though we set the indexTermDivisor to 8 so that when Solr/Lucene is processing a search it will only load every 8th term from the on-disk tii file into memory, the IndexReader that is opened by the IndexWriter does not honor this setting. We opened a JIRA issue (https://issues.apache.org/jira/browse/SOLR-2290).
In the meantime, Robert Muir suggested that we could change the index time parameter "termIndexInterval" . With the default setting of 128, this parameter controls the size of the on-disk tii file by writing only every 128th entry from the tis file into the tii file. Changing the index time "termIndexInterval" parameter required starting the indexing run over from the beginning, but we decided that it was worth doing. We changed the termIndexInterval from the default of 128 to 1024 (128 * 8 =1024).
An Order of Magnitude Speed Up
Once we changed the termIndexInterval, we started over. With the old configuration ramBuffer size of 32MB the average number of documents per segment flush was about 2 (median 1). With the 960MB configuration the average was close to 300. This combined with the other changes produced an order of magnitude increase over the production indexing rate. In production, after the index got over 50GB, the indexing rate averaged about 600 documents per hour per shard. With the new configuration we are getting rates of 10,000-15,000 documents per hour for a single shard, with the average over the entire run of about 10,000 documents per hour.
We had garbage collection logging turned on and saw a total of 10 minutes spent on garbage collection over a period of 72 hours, so we were obviously not running into the GC problems with the ramBuffer size set to 960MB.
Putting the new configuration into production
We assumed that there would be some significant overhead when we implemented this on all 12 shards due to competition for resources and I/O. We are running all 12 shards for indexing on one machine and although we are using several network cards in a configuration that optimially speads the network load across the cards and across storage nodes, at some point competition for network I/O probably saturates the available bandwidth between our machine and the nfs mounted storage network. Even considering this competition we estimated that we could get at least 5,000 documents per hour per shard. Indeed, when we first started indexing with this new configuration we initially got rates of over 60,000 documents per hour (12 shards @ 5,000 =60,000). At this rate we would have been able to re-index the entire 7+ million volumes in 4 or 5 days.
However, as the index size increased and larger merges started to occur the indexing rate went down. At one point we saw in the index logs that several shards were all writing to disk and merging at the same time. To reduce this we configured each shard with a slightly different ramBuffer and MergeFactor configuration ranging from ramBufferSizeMB=320 and mergeFactor=28 to a maximum of mergeFactor=40 and ramBufferSize=960. This temporarily increased the indexing rate, but we still saw very significant slow downs whenever there was a large merge.
The run finished in 10 days, which is a significant improvement over 40. This turns out to be about 30,000 documents per hour for all 12 shard or 2400 documents per hour per shard.
After looking a bit more at the logs we had a "Eureka!" moment (actually more like a Homer Simpson "Doh!" moment). What we noticed is that when indexing against one shard slowed down due to a merge on that shard, after a few minutes, the indexing on all the other shards slowed down. We realized that this was due to our "round-robin" shard selection algorithm. Each producer would quickly run through the jobs for the other 11 shards and then wait on the slow shard before being able to send jobs to the other shards. We took a look at changing the shard selection algorithm and realized that making the required code changes while maintaining high reliability would be somewhat involved. Given other high priority tasks on our TODO lists, we decided that re-indexing 7 million documents in 10 days was good enough. Rewriting our shard selection code is on our TODO when we have time list. When we do the rewriting and put it into production, we will write about it in this blog.
-------------------------
Notes
* I mentioned this large number of one document flushes to some of the Lucene committers at the Lucene Revolution Conference and they suspect this could be the result of a bug. This is currently under investigation.
Büttcher, S., & Clarke, C. L. (2008). Hybrid index maintenance for contiguous inverted lists. Information Retrieval, 11, 175–207. doi:10.1007/s10791-007-9042-8
Büttcher, S., & Clarke, C. L. A. (2005). Indexing time vs. query time: trade-offs in dynamic information retrieval systems. In Proceedings of the 14th ACM international conference on Information and knowledge management, CIKM '05 (pp. 317–318). New York, NY, USA: ACM. doi:10.1145/1099554.1099645
Lester, N., Moffat, A., & Zobel, J. (2008). Efficient online index construction for text databases. ACM Trans. Database Syst., 33(3), 1-33. doi:10.1145/1386118.1386125
Lester, N., Moffat, A., & Zobel, J. (2005). Fast on-line index construction by geometric partitioning. In Proceedings of the 14th ACM international conference on Information and knowledge management, CIKM '05 (pp. 776–783). New York, NY, USA: ACM. doi:10.1145/1099554.1099739