Before we implemented the CommonGrams Index, our slowest query with the standard index was “the lives and literature of the beat generation” which took about 2 minutes for the 500,000 volume index. When we implemented the CommonGrams index, that query took only 3.6 seconds.
After we implemented the CommonGrams Index we looked at the 10 slowest queries for the new index. These queries are different than the slowest queries for the Standard index, because queries containing common words are much faster due to CommonGrams. The slowest query for the CommonGrams index, which took about 9 seconds was the query “histoire de l’art” (entered without the quotes) which is treated by Solr as a Boolean query: “histoire” AND “de” AND “l’art”.
One of the words in this query, "de", is not common in English but is very common in German, Spanish, French, Dutch, and a number of other languages. The word “de” occurred in about 462,000 of the 500,000 documents in the index. The list of common words we used to create the CommonGrams index contained 32 common English words, and the word "de" was not on the list. HathiTrust has content is in over 200 languages with 7 non-english languages having over 70,000 volumes each, and 40 languages having more than 1,000 volumes. (See: Chart of languages for public domain HathiTrustContent.) This indicates a need to consider adding common words in languages other than English to the list of common words for the CommonGrams index.
Solr tools for analysis and performance tuning
Solr has a number of tools that help to determine why queries are slow. We started by using the Solr Administrative tool’s search/query interface and selected “Debug: enable” which runs a Solr debug query. The debug query response shows how the query is parsed and how it is scored.
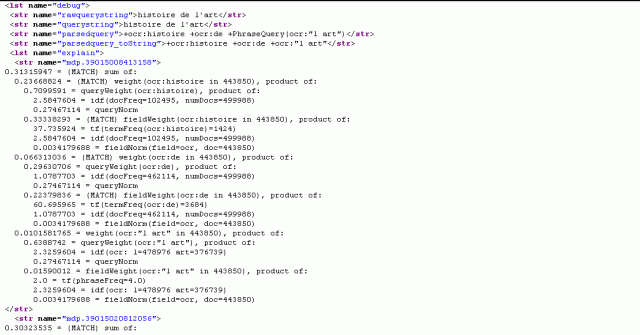
Solr debug query results for "histoire de l'art"
One key bit of information in the debug output is found by comparing the query as it was entered:
<str name="rawquerystring">histoire AND de AND l'art</str>
and the "parsedquery" which shows how the Solr query parser parses the query:
<str name="parsedquery">+ocr:histoire +ocr:de +PhraseQuery(ocr:"l art")</str>
What we discovered is that the word “l’art” was being searched as a phrase query “l art”. Phrase queries are much slower than Boolean queries because the search engine has to read the positions index for the words in the phrase into memory and because there is more processing involved (See : Slow Queries and Common Words for more details).
In order to estimate how much work Solr has to do to process the phrase query for “l art”, we first did a Boolean query for “l AND art” and discovered that those two words occur in about 370,000 out of the 500,000 documents. We then used a tool we developed to determine the size of the positions list for the word “l” and the word “art”. The word “l” occurs about 224 million times in the index and the word “art” occurs about 14 million times. Estimating 1 byte per position entry, this means that the Solr search engine has to read about 238 MB to process the phrase.
In order to determine why the word “l’art” was being turned into a phrase query for “l art”, we used the Solr Administrative tool’s Analysis panel.
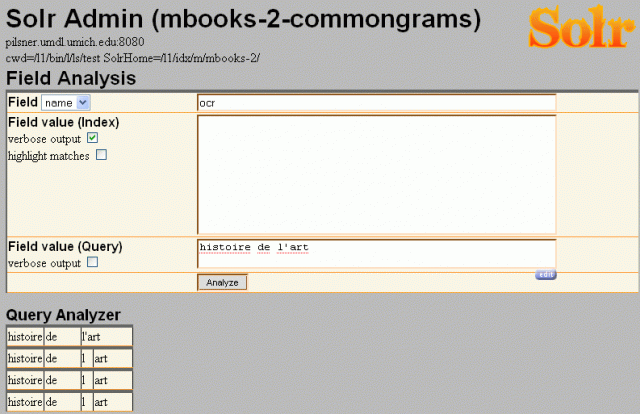
Analysis of query "histoire de l'art"
Selecting verbose output gives more information about each stage in the filter chain
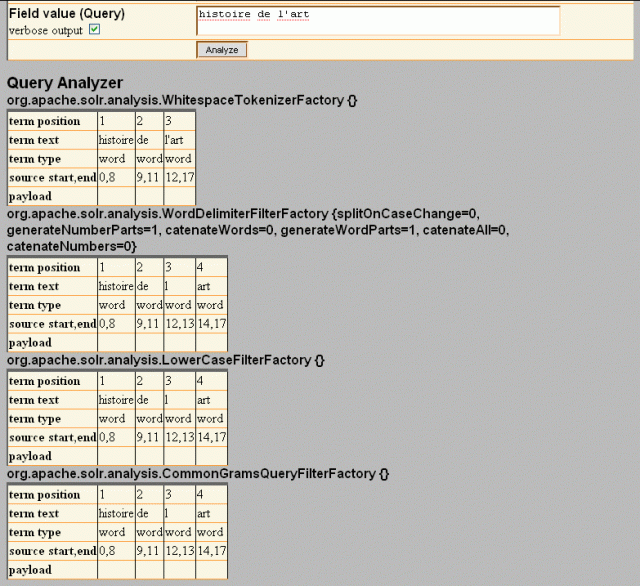
Analysis of query "histoire de l'art" (detailed view)
What we discovered was that one part of our filter chain, the WordDelimiterFilter was splitting “l’art” into two words “l” and “art”. We also discovered that when the filter chain takes a Boolean clause and splits a token into more than one word, the consitutent words get searched as a phrase. This makes sense, but it also slows things down. (Phrase queries require use of the positions list while Boolean queries without phrases do not )
We looked through the other slow queries and discovered several other Boolean queries where one of the words ended up triggering a phase search. For example the second slowest query was “7th International” (without the quotes), which gets searched as a Boolean query “7th AND International”. However, the WordDelimiterFilter breaks the token “7th” into two tokens “7” and “th” and this gets searched as a phrase query. [i].
We took a closer look at what WordDelimiterFilter was doing and discovered that it was creating phrase queries for many words (More details are in the Appendix to this article.)
We decided to replace WordDelimiterFilter with a "punctuation filter" that simply replaces punctuation with spaces. For example “l’art” would be tokenized as a single token: “l art”. This avoids the problem of tokens containing punctuation being split and triggering a phrase query.
We also decided to add more words to the list of common words. In order to come up with candidate words, we did some analysis of the 2500 most frequent words in the 1 million document standard index and our query logs for the beta Large Scale Search. We used the perl Lingua::Stopwords module and looked for stopwords in any of the languages covered by Lingua::Stopwords modules[ii]. We discovered there were 192 unique stopwords in the 2500 most frequent words in the 1 million volume standard index. We also found about 179 unique stopwords in the 11,000 unique queries in our query log. We combined these two list of stopwords with the 200 most frequent terms in the 1 million volume standard index and removed any duplicates from the resulting combined list. The resulting list consisted of about 400 words which we then used as a list of common words to create a new CommonGrams index. The table below compares response times for a 500,000 volume index for the Standard Index, the CommonGrams index with 32 English common words, and the new CommonGrams index with 400 common words and the punctuation filter.
Response time in milliseconds for 500,000 volume index
| Index | Average | median | 90th percentile | 99th percentile |
| Standard Index | 424 | 34 | 142 | 6,300 |
| CommonGrams (32 words) | 140 | 35 | 160 | 3,670 |
| CommonGrams (400 words)* | 87 | 35 | 157 | 1,200 |
*The CommonGrams with 400 common words index also used the punctuation filter instead of the WordDelimiterFilter
Adding more common words and using a filter which strips punctuation but does not trigger a phrase query when a word has punctuation within it, reduced the average response time by nearly 50% and the response time for the slowest 1% of queries by about 2/3rds.
We plan to continute to improve performance through an iterative process using the Solr tools to analyze the slowest queries, making an appropriate change to our indexing process, then using the Solr tools to examine the slowest queries in the new index.
Endnotes
[i] The WordDelimiterFilter by default splits words containing numbers for example "p2p" gets split into 3 words "p" "2" "p". Until a patch in December 2008, there was not a way to turn this off. See https://issues.apache.org/jira/browse/SOLR-876.
[ii] The stopword lists were from the perl module Lingua::Stopwords (http://search.cpan.org/~creamyg/Lingua-StopWords-0.09/lib/Lingua/StopWords.pm) and are based on the stopword lists of the snowball project: http://snowball.tartarus.org/. The languages are:English,French,German, Spanish, Italian, Dutch, Russian, Portugese,Hungarian,, Finnish, Danish, Norwegian, and Swedish.