All Queries are not created equal
We have been running a test suite of 10,000 warm-up queries and 1,000 test queries against indexes of up to 1 million full-text documents. One aspect of our results is that response time for queries varies by several orders of magnitude. For our 1 million volume index, the slowest query took over 2 minutes while the fastest query took less than one thousandth of a second. Thats a ratio of about 100,000 to 1. The chart below shows the response time for our 1,000 test queries on a log scale. The queries are sorted from fastest to slowest.
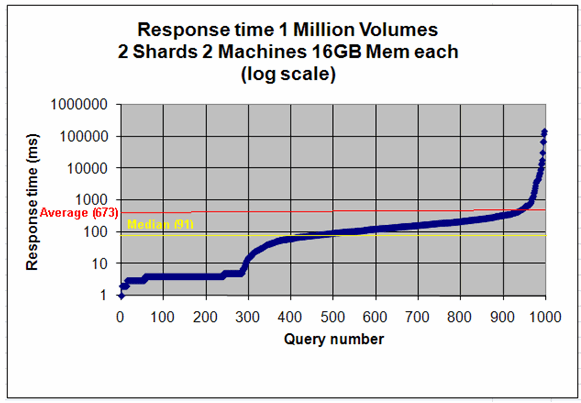
Response time 1 Million Volumes 2 Shards 2 Machines (log scale)
The good news is that 97% of queries took less than a second. The real problem is in the upper right of the chart. About 1% of queries took more than 7 seconds and the slowest 0.5% of queries took between 30 seconds and 2 minutes. From a user-experience point of view, this means that most of the time response time will be just fine, but in one out of 200 times (0.5%), the response time will be unacceptable. [i]
In our experience so far, response time scales linearly with index size, so when we scale up the index to 7 million volumes, if we don't split the index over more machines, the 1% of queries that took between 7 seconds and 2 minutes could take much longer.
Throughput
While it would seem that a response time of under 1 second for 97% of queries is acceptable, these response times are for queries executed one at a time. However, in production we may get new queries faster than Solr can process them. What happens if one of the 0.5% of queries that takes 30 seconds to two minutes is executed and then we get one additional query per second for the next 30 seconds? Those additional queries will be contending with the slow query for resources such as disk access, cpu, and memory. In our load testing we found that as the number of queries per second was increased over 1 query per second, the average response time got significantly worse. So we now have two problems related to slow queries:
- With the 1 million document index, one out of 200 queries will have unacceptable response time. This could get worse as we scale up to 7 million documents.
- When multiple simultaneous queries are sent to the server, the slow queries contend for resources with other queries and lower overall throughput.
There is one additional problem which is that disk access's required to process the slow queries cause "cache pollution" which results in subsequent queries being slower than they would be otherwise. We will discuss cache pollution shortly.
Why are some queries significantly slower?
The short answer is "more disk seeks". The slowest queries are phrase queries with commonly occurring words such as "a", "of", "the", "and", "an", etc. Queries with common words take longer because the data structures containing the lists of documents containing those words in the index are larger. For example, in our 1 million document index, the word "the" occurs in about 800,000 documents whereas the word "aardvark" occurs in 1,500 documents. In processing a query, the search engine has to look at the list of document ids for each word in the query and determine which documents contain all of the words. The longer the lists, the more data must be read from disk into memory and the more processing must be done to compare the lists. (See the appendix in the Large-Scale-Search report or : http://nlp.stanford.edu/IR-book/html/htmledition/a-first-take-at-building-an-inverted-index-1.html and http://nlp.stanford.edu/IR-book/html/htmledition/processing-boolean-queries-1.html )
Phrase queries take longer than Boolean queries because when the search engine processes phrase queries it needs to insure not only that all the words in the query are in a document, but that the words occur in the document adjacent to each other and in the same order as the query. In order to do this the search engine needs to consult the positions index, which indexes the position that each word occurs in each document. See ( http://nlp.stanford.edu/IR-book/html/htmledition/positional-postings-and-phrase-queries-1.html )
While the size of the postings index is proportional to the number of documents in the index, the size of the positions index is proportional to the total number of words in the index. Thus the number of documents in the collection times the average number of words in a document provides a measure of the size of the positions index. The average number of words in our documents is around 100,000 words. Full-text books tend to be longer than web pages, a common document type for information retrieval research. In contrast to most of the large test collections used in information retrieval research, our documents are comparatively very large. The chart and table below compare average document sizes of the HathiTrust collection with several research test collections designed for testing large scale information retrieval.[ii]
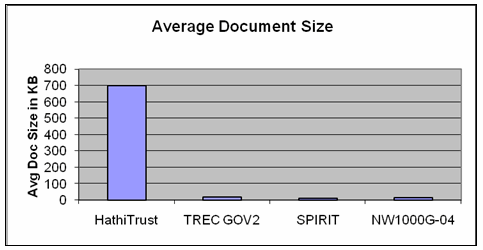
Average Document Size for Test Collections
Collection | Size | Documents | Average Doc Size |
HathiTrust | 4.5TB* | 7 million* | 700KB |
0.456 TB | 25 million | 18KB | |
1 TB | 94 million | 10KB | |
1.3TB | 100 million | 16KB |
* Projected size by 2010
Because our documents are so long, in our Solr/lucene indexes, the positions index which is used for processing phrase queries is about 85% of the total index size. In comparison the postings index which is used for Boolean queries and in the initial processing of Phrase queries is about 12% of the total index size.
We can see how these issues play out by looking at the slowest of our test queries, the phrase query : "the lives and literature of the beat generation." [iii] In the chart below we show the number of documents containing each term, an estimate of the size of the postings list, the total number of times the term occurs in the entire 1 million volume corpus, and an estimate of the size of the positions list (for the 1 million document index.) Note that the postings list sizes are in Kilobytes, while the position list sizes are in Gigabytes.[iv]
Word | Number of | Postings list | Total Term Occurrences | Position list |
| Documents | Size(KB) | (Millions) | Size (GB) |
the | 800,000 | 800 | 4,351 | 4.35 |
of | 892,000 | 892 | 2,795 | 2.8 |
and | 769,000 | 769 | 1,870 | 1.87 |
literature | 453,000 | 453 | 9 | 0.13 |
generation | 414,000 | 414 | 5 | 0.01 |
lives | 432,000 | 432 | 5 | 0.01 |
beat | 278,000 | 278 | 1 | 0.01 |
Total |
| 4,037 |
| 9 |
To process "the lives and literature of the beat generation" as a Boolean query about 4 megabytes of data would have to be read from cache or disk. To process the phrase query, nearly 9 gigabytes of data has to be read from cache or disk.
Cache Pollution
The difference in the amount of data needed for processing a normal (Boolean "AND") query and a phrase query has interesting implications for caching. Because reading data from disk is several orders of magnitude slower than getting data from memory, search engines implement caching schemes to keep frequently used data in memory. Solr, the search engine we use for Large Scale Search, relies on the operating system's disk cache to cache data from the postings list and position list. This is why two of the more frequently suggested performance tuning tips on the Solr mailing list are:
- Make sure that the server has enough memory to fit most of the index into memory
- Run a large number of "realistic" queries against the server to warm the cache before doing performance testing.
(See : http://www.nabble.com/Re%3A-Help-optimizing-p17074425.html )
The size of our 1 million volume document index is about 225GB, which means that only a fraction of the index will fit into the total 32GB of memory we have in our test machines. What this means is that once the cache is full, each further query causes some data to be evicted from the cache. This is the normal way caches work and the end result after a reasonable number of queries have been run, is that data for the most frequently occurring words in queries tends to be in the cache.
Phrase queries are generally between 3-10% of all queries (Spink & Jansen, 2005) and about 5% of all queries in our test query sets. From the previous analysis of our slowest query we can estimate that the upper limit of the amount of data that needs to be read for a Boolean query is in the range of a few megabytes whereas the upper limit of the amount of data that needs to be read for a phrase query is in the range of 9GB. The total memory available for caching the postings and positions list in our system is about 30GB (we allocate 2GB for Tomcat and Solr.) Since Boolean queries occur much more frequently and result in smaller amounts of cached data, a phrase query containing common words could potentially evict a very large number of postings from Boolean queries from the cache. The end result is that the phrase query with common words "pollutes" the cache, and the processing for a large number of subsequent Boolean queries which might have been able to read data from the cache will instead have to re-read data from the disk. Thus, slow phrase queries increase the response time for a large number of subsequent Boolean queries.
Summary
The slowest queries are phrase queries containing common words. These queries are slow because the size of the positions index for common terms on disk is very large and disk seeks are slow. These long positions index entries cause three problems relating to overall response time:
- With the 1 million document index, one out of 200 queries will have unacceptable response time. This could get worse as we scale up to 7 million documents.
- When multiple simultaneous queries are sent to the server, the slow queries contend for resources with other queries and lower overall throughput.
- Since the positions lists for common words are so large, phrase queries containing common words pollute the cache and cause a large number of subsequent queries to be slower than they would otherwise be, increasing the average response time for all queries.
Coming next- Dealing with common words: Stop words, bigrams and commongrams
References
Spink, A., & Jansen, B. (2005). Web Search: Public Searching of the Web. Springer Netherlands. 2005.http://dx.doi.org/10.1007/1-4020-2269-7.
Endnotes
[i] General guidelines for computer interfaces suggest that response times of more than 10 seconds are distracting to users. How long a user is willing to wait varies. For more information see the following:
- http://www.useit.com/papers/responsetime.html
- http://www.humanfactors.com/downloads/apr01.asp#
- Seow, Steven C. (2008) Designing and Engineering Time: The Psychology of Time Perception in Software. Addison-Wesley Professional, 2008.
- http://www.websiteoptimization.com/speed/1/
[ii] To be fair, it must be noted that research test collections may limit the total collection size in order to facilitate sharing the collections among researchers A possible exception is the collection for this year's TREC web track, clueweb09, which features a 25TB collection of 1 billion web pages. This is certainly a very large collection. However the average document size for the clueweb09 collection is only about 24KB. (See: http://boston.lti.cs.cmu.edu/Data/clueweb09/ .) The recent INEX Book track is the closest match with HathiTrust in the size of documents , however, their total collection size is 50,000 documents with a total text size of about 50GB. See Kazai et.al. (2008) "Overview of the INEX 2008 Book Track" in INEX 2008 Workshop Pre-Proceedings. Available at: http://www.inex.otago.ac.nz/data/proceedings/INEX2008-preproceedings.pdf. For more background on the INEX book tracksee: http://www.inex.otago.ac.nz/tracks/books/books.asp and http://research.microsoft.com/en-us/projects/booksearch/default.aspx.
[iii] This is the subtitle of a book: "Naked Angels: The Lives and Literature of the Beat Generation"
[iv] We wrote a command line utility to read the index and output the number of documents containing a term and the total number of occurrences of the term in the corpus. (https://issues.apache.org/jira/browse/LUCENE-2393 ). To estimate the sizes of the postings and positions list, we simply multiplied the number (of the number of documents, or number of occurrences) by 1 byte. Actually the index stores only the difference between a document id and the document id preceding it in the list encoded in a variable byte encoding using from 1 to 4 bytes. The same logic holds for word positions. Our procedure probably underestimates the sizes as one byte only holds values from 0 to 127 and its likely that the difference between the position of a word and the subsequent position of the next occurrence of the word would be greater than 127 for many words. For more information on the data structures used in the Lucene index see Apache Lucene - Index File Formats