Zephir, the HathiTrust Metadata Management System
The University of California (UC) California Digital Library (CDL) currently manages bibliographic metadata for HathiTrust in a system called Zephir, designed for HathiTrust and launched in the fall of 2013. Prior to digital content being ingested to the HathiTrust repository, records describing that content must be submitted to the system. Zephir ingests, stores, and manages bibliographic metadata from HathiTrust contributors and exports this data for use in other HathiTrust systems, including the ingest framework and online catalog. Zephir performs a range of functions, including record ingest and updating, general management of records, record versioning, and reporting on record loading, including error reporting. In addition to managing bibliographic records, Zephir also includes a database of metadata values mapped from these records, as well as management data, that supports analysis.
Zephir’s implementation highlights the modularity of the HathiTrust repository, the capacity for distributed development of repository infrastructure, and a successful collaboration between University of California CDL staff, HathiTrust staff, and staff at the University of Michigan working in direct support of HathiTrust.
California Digital Library's Zephir Team
Charlie Collett, Technical Lead
Claudia Conrad, Product Manager
Barbara Cormack, Metadata Analyst
Sarah Houghton, Director, Discovery and Delivery Team
Jing Jiang, Programmer
HathiTrust/University of Michigan Staff
Natalie Fulkerson, Collection Services Librarian, HathiTrust
Sandra McIntyre, Director of Services and Operations, HathiTrust
Tim Prettyman, Senior Library Applications Programmer, University of Michigan
Jon Rothman, Head of Automated Indexing and Metadata, University of Michigan
Zephir System Documentation
Metadata Submissions
Once a contributor has initiated planning for HathiTrust content submission with HathiTrust staff, they will work with CDL Zephir staff to submit metadata for that content. An overview of the bibliographic metadata submissions process is here: https://www.hathitrust.org/bib_data_submission. Prior to metadata processing, contributor records are submitted to Zephir via FTPS.
Metadata Processing
Submitted contributor metadata is processed by a record loader script (written in Perl) and subsequent import/update scripts (written in Ruby). Metadata processing includes validation against the MARC standard and HathiTrust bibliographic metadata specification (https://www.hathitrust.org/bib_specifications). During processing, some metadata values are normalized, put into consistent locations, removed, or added. Contributors are provided with reports detailing the condition of submitted records and success of their loading. Ingested records are scored based on the presence or absence of data in MARC metadata fields. When records that each describe multiple submitted copies of a given title (usually from multiple institutions) the record with the highest score will be exported for inclusion in the HathiTrust catalog.
Metadata Storage (file systems and database)
Zephir (written in Ruby) stores the original biliographic records for each volume as submitted by HathiTrust contributors and as processed during loading. When metadata is updated, all record versions are stored in a file system and Zephir maintains a complete history of all changes to a record (using Git and Pairtree file structure). Selected data elements are stored and indexed in a database (using MySQL), which also includes bibliographic records for each volume.
Metadata Export
Zephir exports bibliographic records and management data for HathiTrust workflows and services (with Ruby). Zephir also has the capacity for exporting distinct records for each volume as well as specified metadata for analysis and reporting.

Zephir interactions with other HathiTrust systems
Export to HathiTrust Ingest Framework
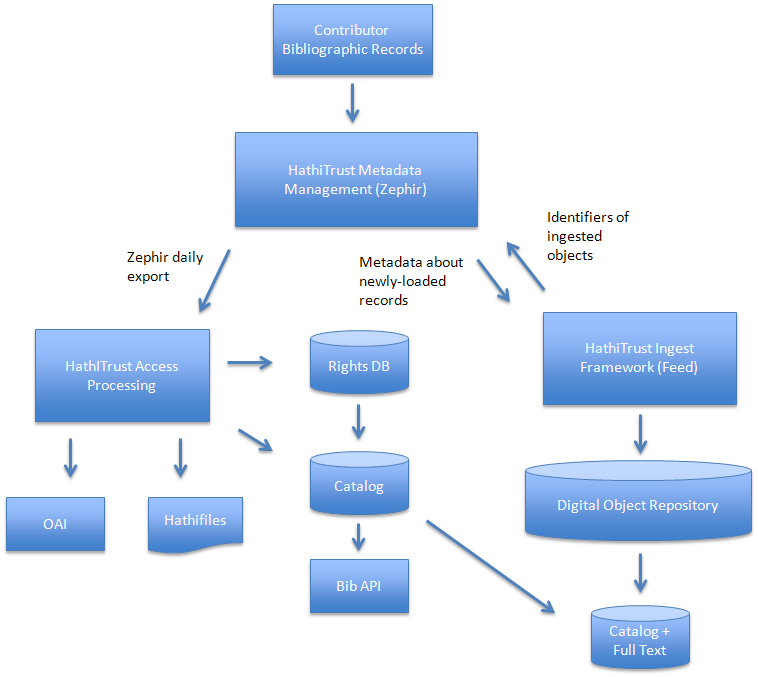
On a daily basis, Zephir exports a list of volume identifiers and additional metadata to the University of Michigan for newly loaded and newly updated records from contributors. The HathiTrust Ingest Framework (Feed) utilizes this information in the digital repository ingest process.
Import from HathiTrust Ingest Framework
On a daily basis, Zephir receives a list of volume identifiers from the University of Michigan originating in the HathiTrust Ingest Framework (Feed) representing digital objects ingested to the HathiTrust repository the previous day.
Export to HathiTrust Catalog
Zephir uses a list of volume identifiers from the University of Michigan representing digital objects ingested to the HathiTrust repository the previous day to determine which bibliographic records are included in its daily export to the University of Michigan for further processing and use in HathiTrust’s access systems.
Zephir Background
Bibliographic information is critically important to HathiTrust. Bibliographic records provide general descriptions of items (title, author, publisher, date), as well as summaries, descriptions and additional information that are often not available in the item itself (e.g., author death date, subject headings, government document status). This information is crucial for helping users find what they are looking for, allowing HathiTrust to make an initial automated rights determination about volumes (with millions of volumes in the repository, HathiTrust could not provide the broad access it does otherwise) and perform manual investigations into the copyright or in-copyright status of items. It is also used in inventories of HathiTrust items, to trigger ingest, and to trouble-shoot problems.
In 2013, HathiTrust released a new bibliographic metadata management system, called Zephir, to store, manage, and export to other HathiTrust systems, bibliographic records accompanying digital items deposited into HathITrust's digital repository. Zephir performs a wide range of functions, including record ingest and updating, general management of records, record versioning, and reporting on record loading, including error reporting. Zephir integrates seamlessly into HathiTrust workflows, providing metadata that is used for all the purposes above, being primarily accessible through HathiTrust's online catalog, datafeeds, and APIs.
Zephir includes a number of additional functions:
- Zephir stores all records successfully submitted by contributing institutions, allowing for access to a broad range of complementary bibliographic metadata for future use.
- Zephir exports a preferred base record with holdings to be made available through the HathiTrust public access catalog. Zephir uses a scoring algorithm to weight the presence or absence of MARC fields and field values to determine base record selection. Base records exported from Zephir can change based on adjustments to the scoring algorithm or based on the quality of updated or additional records.
- Zephir supports versioning and retains all successfully submitted or updated copies of records describing digitized resources in the HathiTrust repository. The system has been designed to include "shadow" records which will allow for retaining the integrity of originally submitted metadata should changes need to be made by HathiTrust and not the contributing institution. Shadow records are currently only applied to affect critical changes affecting rights per the HathiTrust Bibliographic Correction Policy: https://www.hathitrust.org/bib_metadata_correction
- Metadata field values critical for management and analysis from all contributed records are mapped to a HathiTrust-specific metadata schema, and stored in a SQL database and as XML files.
In preparation for launching Zephir, HathiTrust implemented revised bibliographic metadata specifications (https://www.hathitrust.org/bib_specifications) as well as new bibliographic metadata submission processes (https://www.hathitrust.org/bib_data_submission) that provide contributors with feedback about their records through a series of reports generated for each file submitted.
California Digital Library
The University of California (UC) is a founding member of HathiTrust, and the California Digital Library (CDL) has historically been a locus of coordination and technical development for the UC Libraries. A team at CDL developed Zephir to support specific HathiTrust requirements by working in consultation with staff at the University of Michigan who managed HathiTrust bibliographic metadata from HathiTrust's inception until 2013. The work of designing and implementing Zephir highlighted the modularity of the HathiTrust repository, the potential for collaboration between HathiTrust member institutions in developing components of the infrastructure, and the capacity for distributed development of repository infrastructure in addition to the core systems and services provided by the University of Michigan.
Zephir Launch Announcements
https://www.hathitrust.org/zephir_announcement
Project Goals
- Provide equivalent metadata management functionality to the University of Michigan Aleph-based system.
- Provide improved update, match and merge record management functionality to the HathiTrust.
- Provide a flexible framework for the management of metadata at many levels (e.g.: work, manifestation, item)
- Position the HathiTrust to respond to metadata management challenges raised by duplicate and surrogate records.
Project Team
The launch of Zephir was a multi-year effort, participated in by a wide range of staff at the CDL and the University of Michigan. Team members involved in Zephir's original development and launch included:
University of California
Lynne Cameron, HathiTrust Co-Technical Lead (core development team)
Heather Christenson, HathiTrust Project Manager
Charlie Collett, Technical Project Lead (core development team)
Paul Fogel, HathiTrust Co-Technical Lead
Patricia Martin, Director, Discovery and Delivery Team
Kathryn Stine, Metadata Analyst & Project Manager (core development team)
Michael Thwaites, Programmer & Testing Coordinator (core development team)
Lena Zentall, Project Manager (core development team)
University of Michigan
Bill Dueber, Library System Programmer
Tim Prettyman, Senior Library Applications Programmer
Jon Rothman, Head of Library Systems Office
Jeremy York, Assistant Director, HathiTrust
Executive Sponsors and Coordinators
Laine Farley, Executive Director, California Digital Library; HathiTrust Executive Committee member
John Wilkin, Executive Director, HathiTrust