In part 1 we talked about why some queries are slow and the effect of these slow queries on overall performance. The slowest queries are phrase queries containing common words. These queries are slow because the size of the positions index for common terms on disk is very large and disk seeks are slow. These long positions index entries cause three problems relating to overall response time:
- With the 1 million document index, one out of 200 queries will have unacceptable response time. This could get worse as we scale up to 7 million documents.
- When multiple simultaneous queries are sent to the server, the slow queries contend for resources with other queries and lower overall throughput.
- Since the positions lists for common words are so large, phrase queries containing common words pollute the cache and cause a large number of subsequent queries to be slower than they would otherwise be, increasing the average response time for all queries.
There are several strategies for dealing with the problems caused by the size of the positions index entries for common terms.
Stop Words
One approach to dealing with slow queries due to common words is to create a list of “stop words” and process both incoming queries and the indexing process to ignore those words. This strategy was employed in the early days of information retrieval in order to keep index sizes relatively small. In general “stop words” are frequently occurring words that don’t add much specificity to the query. For example, since the word “the” occurs in 80% of the documents, it does not help much to narrow down search results. However, in a phrase query, a stop word or series of stop words may be important to the query and in combination they may result in a phrase which is very specific. One such phrase is “to be or not to be”. Some other queries that would be difficult or impossible if stop words are removed from queries and the index are[i]:
- “the who”
- “man on the moon” vs “man in the moon”
- “being there”
We have an additional problem in that we are currently indexing multiple languages in one index. A stop word in one language is often a content word in another. For example the German word “die” is a stopword in German but a content word in English. The words: “is” and “by” are stopwords in English but content words in Swedish (ice and village respectively). Because of these considerations, we would like to avoid removing stopwords from our index.
Bigrams and CommonGrams
There are several approaches to dealing with optimizing the performance of phrase queries containing common terms other than removing stop words. Some of them such as nextword indexes and phrase indexes(Chang & Poon, 2008; Williams, Zobel, & Bahle, 2004)), involve special indexing data structures and custom query processing, which would require serious hacking deep in the bowels of Solr/Lucene to implement. However there are two approaches that can be easily implemented as custom filters in Lucene. They are bigrams, (The Solr Shingle filter implements bigrams) and CommonGrams. The CommonGrams approach has been implemented in the Nutch project, an open-source web crawler and search engine based on Lucene. A similar approach is used in the California Digital Library’s XTF .
Bigrams work by combining every two words into one token. For example the slow query: “The lives and literature of the beat generation” would generate the following tokens:
“the-lives” “lives-and” “and-literature” “literature-of” “of-the” “the-beat” “beat-generation”.
The advantage of this is twofold. First, for a two word phrase query such as “beat generation”, the position index does not need to be consulted since the two words are indexed as one token. ( Studies of web logs have found that a very large proportion of phrase queries are two word queries.) Second, for phrase queries containing three or more words the position lists are shorter. (Phrase queries containing more than two words require consulting the position index since a single bigram only can match 2 of the 3 or more words of a query.) As an example of the comparitive size of the position list for a regular index compared to a bigram index, the position list for the token “the-lives” will be much shorter than the position list for “the”. The disadvantage of the simple bigram approach is that each word (with the exception of the first and last word in each document) gets indexed 3 times: Once by itself (all words are also indexed as unigrams in order to allow single term queries), once as the first word of a two word pair, and once as the second word of a two word pair. This means the size of the index is three times as large as an index without bigrams. Since we are mostly concerned with the position lists for very common words, we can get almost the same performance benefit as bigrams by only creating bigrams for two word pairs where one or both of the words is a stop word (or common word). To implement this approach we ported the Nutch CommonGrams algorithm to Solr : (https://issues.apache.org/jira/browse/SOLR-908.) We implemented a test index of 500,000 volumes using CommonGrams and compared it with a standard 500,000 volume index. The CommonGrams index (using 32 common words based on the Solr/Lucene StopFilter list), was 40% larger than the standard index.
The two charts below show the total number of occurrences of a token in the 500,000 volume index for the standard index and the index with CommonGrams.[ii]
| Standard Index | ||
| Term | Total occurrences in corpus (millions) | Number of Docs (thousands) |
| the | 2,013 | 386 |
| of | 1,299 | 440 |
| and | 855 | 376 |
| literature | 4 | 210 |
| lives | 2 | 194 |
| generation | 2 | 199 |
| beat | 0.6 | 130 |
| CommonGrams Index | ||
| Term | Total occurrences in corpus (millions) | Number of Docs (thousands) |
| of-the | 446 | 396 |
| generation | 2.42 | 262 |
| the-lives | 0.36 | 128 |
| literature-of | 0.35 | 103 |
| lives-and | 0.25 | 115 |
| and-literature | 0.24 | 77 |
| the-beat | 0.06 | 26 |
The 3 most common terms in the query: “the”,”of” and “and” occurred a total of almost 4 billion times in the standard index. In contrast the most frequent term in the CommonGrams version of the query “of-the” occurred 446 million times with the rest of the terms all under 3 million times.
We ran tests against the two indexes. Below is a chart showing the improvements in query response time for a 500,000 document index using the standard index and for a 500,000 document index using CommonGrams with 32 common words used in the standard lucene/Solr stopfilter. The average response time went from 459ms to 68ms.
For the slowest 0.5% of the queries (queries taking from 10 seconds to 2 minutes with the standard index) the CommonGrams index reduced them all to below 8 seconds.
Comparison of 500 thousand document indexes (Response time in milliseconds)
| average | median | 90th percentile | 99th percentile |
Standard 500K Docs | 459 | 32 | 146 | 6,784 |
CommonGrams 500K Docs | 68 | 3 | 71 | 2,226 |
The chart below which is plotted on a logarithmic scale shows that the ratio of response times varies from a reduction of about 50% down to a reduction of 95%. For a detailed breakdown see Appendix 1
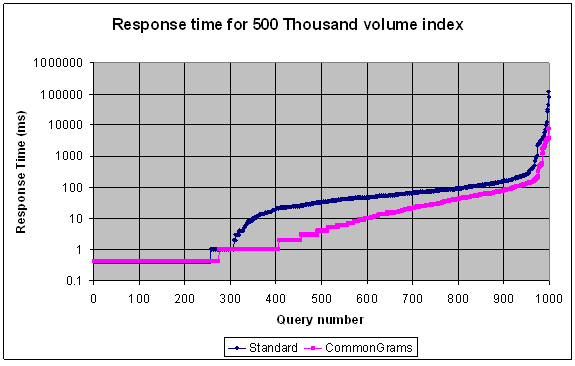
Response time 500,000 Documents (log scale)
The chart below which is also plotted on a logarithmic scale, shows the slowest %1 of the queries. The slowest 0.5% of the queries were between 10 seconds and 2 minutes for the Standard index, but were reduced to between 5 and 10 seconds for the CommonGrams index.
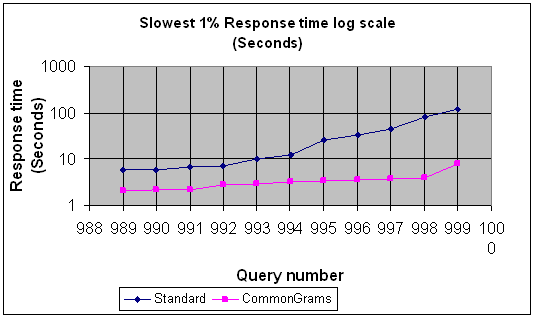
Response Time Slowest 1% of queries
If we add more words to the list of common words, we should get better performance, but the size of the index will increase. The CommonGrams index built with a 32 word list of common words is about 40% larger than the Standard index. We are currently experimenting to try to characterize the trade-off in increased performance with more words added to the common words list versus the increased index size.
References
Chang, M., & Poon, C. K. (2008). Efficient phrase querying with common phrase index. Information Processing & Management, 44(2), 756-769. doi: 10.1016/j.ipm.2007.06.003.
Williams, H. E., Zobel, J., & Bahle, D. (2004). Fast phrase querying with combined indexes. ACM Trans. Inf. Syst., 22(4), 573-594. doi: 10.1145/1028099.1028102.
Endnotes
[i]Walter Underwood the software engineer responsible for the Solr implementation at Netflix has a list of examples based on movie titles: http://wunderwood.org/most_casual_observer/2007/05/invisible_titles.html
[ii] We wrote a command line utility to read the index and output the number of documents containing a term and the total number of occurrences of the term in the corpus. To estimate the sizes of the postings and positions list, we simply multiplied the number (of the number of documents, or number of occurrences) by 1 byte. Actually the index stores only the difference between a document id and the document id preceding it in the list encoded in a variable byte encoding using from 1 to 4 bytes. The same logic holds for word positions. Our procedure probably underestimates the sizes as one byte only holds values from 0 to 127 and its likely that the difference between the position of a word and the subsequent position of the next occurrence of the word would be greater than 127 for many words. For more information on the data structures used in the Lucene index see Apache Lucene - Index File Formats
Comments
commongrams versus stopwords
Lots of great information on
DefaultSimilarity.setDiscountOverlaps(true)
DefaultSimilarity.setDiscountOverlaps(true)
Hi Otis,
Haven't had a chance to experiment with this yet. Its on my list of experiments once we get our new test server set up. I think the hard part will be finding good test cases with our data. I'm also interested in trying to determine if we have to tweak the default length normalization because we have such long documents. I plan on looking at SweetSpot Similarity. We really haven't started looking at evaluating/tweaking relevance ranking yet.
Tom
CommonGrams performance
CommonGrams performance
Hi Salman,
You are the second person to comment on an unexpected decrease in performance with CommonGrams, so I'm interested in trying to determine the cause.
CommonGrams should improve performance for simple phrase queries containing common words if your bottleneck is disk I/O for reading the positions index. How large is your 200K word index? How large is your *prx file?
You should see faster response times for simple phrase queries. Are you getting slower response times for simple phrase queries? What kinds of queries are slower with the CommonGrams index?
Its possible that wildcard queries may be slower with the CommonGrams index due to the increase in the number of unique terms and CommonGrams will probably not work properly with proximity searches, although I don't remember enough of the implementation details of proximity searches and slop factors to tell you in what cases they will and won't work.
As far as the increase in index size, we saw a 50-60% increase in index size. I wonder if there is some interaction with your filter chain.
Tom
Thanks for the quick
CommonGrams performance
Hi Salman,
Would it be all right with you to move this discussion to the Solr list (solr-user@lucene.apache.org )? That way you can get feedback from other CommonGram users who may have more experience with complex queries and proximity queries. Also if we move to the list, Toke Eskildsen, who has done extensive experiments with SSD's can help answer your questions about the benefit of SSD's.
In our experience experiments on small indexes (10GB or less), could not reliably indicate the performance of larger indexes (100GB or more). In particular, with the large indexes the impacts of disk I/O are much more apparent.
As far as complex queries, please give some examples. Wildcard queries could be slower with CommonGrams due to the increase in the number of unique terms.
>>either the times are quite close or in case of a difference the non-CommonGrams >>would take few hundred milliseconds and CommonGrams 1-2 sec.
Can you give an example query where the CommonGrams version is significantly slower? Also a debug/explain query might help to see if there are interesting analyzer issues.
>>currently for testing purposes we got 1000 words with highest frequencies (what shows up in Luke). We would be discarding few of them but is that the right strategy? as I think Luke shows the occurrence in no. of documents NOT the total occurrences?
Yes Luke shows the terms with the highest document frequency, not the highest number of occurrences. We contributed a patch to org.apache.lucene.misc.HighFreqTerms (LUCENE-2393)that will list the terms with the highest total occurences. If you are using a 3x version of lucene you can use the -t flag. However, in order to limit the search space it starts with the top terms by document frequency. So to get the top 1000 terms by occurrence frequency you can ask for the top 10,000 with the -t flag and take the first 1,000 from the resulting list. (Assuming that you don't have a few documents that repeat a term a zillion times)
java org.apache.lucene.misc.HighFreqTerms [-t][number_terms] [field]
( http://svn.apache.org/viewvc/lucene/dev/branches/branch_3x/lucene/contri...)
Let me know if its ok to move this to the list and I'll start a thread.
Tom
Add new comment